

“Big reputation, big reputation, ooh you and me we’ve got big reputations.” Taylor Swift released her sixth studio album, Reputation, in November last year. The old Taylor is dead, and in her place is a new, edgier Taylor, toughened from the years of media scrutiny, turbulent relationships and high-profile celebrity feuds. Whether you like the album or not (personally, I love it), this article is not really about Taylor Swift. This is about my first experience delving into the world of Twitter scraping.
Twitter was created in 2006 and has grown into a worldwide social network with around 335 million active users in 2018. Twitter, along with other social media giants such as Facebook, YouTube, LinkedIn, and Instagram, has revolutionised the way we share news and interact with friends and celebrities. Each day we leave behind a trail of our virtual movements, including comments, likes, and the pages we view. Companies are eager to collect this data and use it to provide customer insight and improve products and services. For example, a company can search for tweets mentioning their name to see how they are perceived by the public, or they can analyse their followers to look for patterns and expand their presence online. Accessing data in this way is often called social media mining.
Social media mining is not just for big corporations or academics. With open-source software such as R or Python, we can all access social media data and use it in our own projects. Each social media site has a slightly different way of accessing data, but for this case study I am focusing on one of the most straightforward ways, using Twitter. Twitter is a great place to start as, unlike other platforms, almost all users’ tweets are public and accessible. You can pick any topic to scrape data on, and, as an example, I decided to focus on a celebrity with a huge Twitter presence – Taylor Swift. Since her latest album focuses on her supposedly “bad” reputation, I was interested to find out how she’s perceived on this particular social network.
To extract data from Twitter, you can use the company’s application program interface (API), which, in simple terms, is a software intermediary that allows two applications to talk to each other. In our case, the API allows us to access Twitter data and bring it directly into our program in the format we want. There are packages available in both R (twitteR) and Python (tweepy) that make accessing the API and analysing specific tweets straightforward. Before you start, you need to sign up for your own Twitter access keys. This is free, but you need your own Twitter account and a little bit of time to go through the steps. Extracting tweets can then be done with a few lines of code. All you need is a keyword (or more than one, if you like), the number of tweets you want to pull and the type of tweets (most recent or most popular for example).
After extracting tweets, the next step is to perform some simple text-cleaning. In R this can be done using the package tm. Example steps might include removing numbers, punctuation, emoticons and blank spaces, or changing all letters to lowercase and removing non-interesting words, for example, the key words you searched with and small words such as “and” or “of”, known as stop words.
For my project, I extracted 10,000 tweets that contained Taylor’s Twitter username, @taylorswift13. I decided to use the username as this meant all the tweets I extracted were directly targeted at her account, as opposed to merely mentioning her name as part of some wider context. This resulted in a more relevant sample of tweets than when using search terms such as “Taylor Swift”. I selected only tweets that were in English (although they could be from anywhere in the world) and requested a mixture of popular and real-time tweets. Including popular tweets is a good idea as these tend to come from influential Twitter users (that is, users with lots of followers – the number can vary but, in general, they have over 1,000 followers). However, I found that only including popular tweets meant there were not enough tweets to get a large sample. Using a mixed approach (popular and most recent) gave me enough tweets and included the more influential posts. My tweets were extracted on 2 April 2018; the most recent was from 2pm on 2 April 2018 and the oldest was at 12:50am on 31st March 2018, covering three days of social interactions in the Twitter network. (Note that the standard version of the Twitter API only searches a sample of tweets from the last 7 days, however Twitter has premium versions that supports older tweets.)
After cleaning the data, I started by having a look at the most common words relating to Taylor Swift. I produced a word cloud, using the R wordcloud package, from all of the 10,000 tweets, and the result is shown below. The most common words include the name of her music video, “Delicate”, words relating to her music and sales, such as “video”, “spotify” (the music streaming service) and “chartdata”, and other miscellaneous words like “now”, “top” and “since”. This gives some insight into the sorts of things people were saying about Taylor at the time, but it does not reveal much about her reputation or the feelings people have towards her.

In the lead up to the album’s release, Taylor made much of her supposedly “bad” reputation. As reported by Vox: “Swift announced Reputation by deleting all of her old social media posts, replacing them with a video of a snake hissing, in what appeared to be a reference to her reputation as a lying snake.” But does Taylor really have a bad reputation on Twitter?
To answer that, we could consider the sorts of things people are saying about her. Are the comments nasty or nice? Do they talk about her love life and celebrity feuds, as her music would have us believe? With just a few tweets to analyse, you could easily read through each post individually and classify them according to whether the author was slating her or raving about her. However, with a list of thousands of tweets, this becomes more difficult.
One solution is to use text sentiment analysis. The idea is that you split a sentence into words and look to see how many positive and negative words are in that sentence. There are different methods of calculating the sentiment: the method I chose was to look for words from pre-chosen dictionaries of positive and negative words (I used the “bing” dictionary from the tidytext package). In each of my sampled tweets, a positive word was given +1 and a negative word was given -1. The individual word scores are then summed, with the result indicating whether the tweet is overall positive or negative. There are drawbacks to this method: for example, if a sentence contains the phrase “not good” this is scored as +1 even though it is a negative phrase. More complex algorithms are available that can help address these types of issues. However, I chose this basic method for the sake of simplicity.
Having scored all tweets, I could then calculate summary statistics. I found that the mean positivity score was 0.68 with a standard deviation of 0.84. The distribution of scores is shown in the bar-plot below.
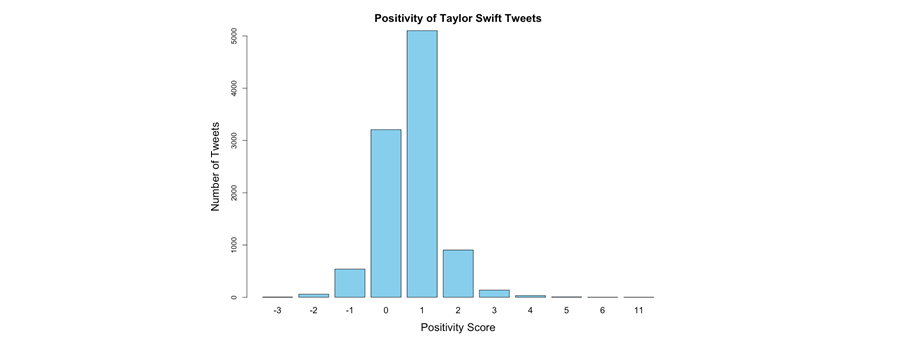
So, what does this tell us? Well, overall, the tweets are positive. People are saying more nice things than negative – things aren’t as bad as you think, Taylor! But of course, that is just the average score; we can see from the graph that there are negative tweets out there. In addition, reputation tends to be relative. Perhaps if other related artists have much higher mean sentiment scores and less negative tweets about them then we might understand why Taylor feels she has a bad reputation.
I re-ran the same analysis looking at other celebrities, comparable to Taylor, who also have a large following on Twitter. For each one, I pulled 10,000 tweets based on their Twitter handle. All tweets were extracted on 2 April 2018. The most recent were on the date of the extraction and the oldest ranged from 25 March for Selena Gomez to 1 April 2018 for Harry Styles, thus covering similar periods of time. The table below shows the summary statistics (ordered by mean score) for Bruno Mars, Demi Lovato, Louis Tomlinson, Kim Kardashian, Beyonce, Taylor Swift, Justin Bieber, Liam Payne, Ariana Grande, Niall Horan, Justin Timberlake, Harry Styles, Katy Perry, Selena Gomez and Miley Cyrus.
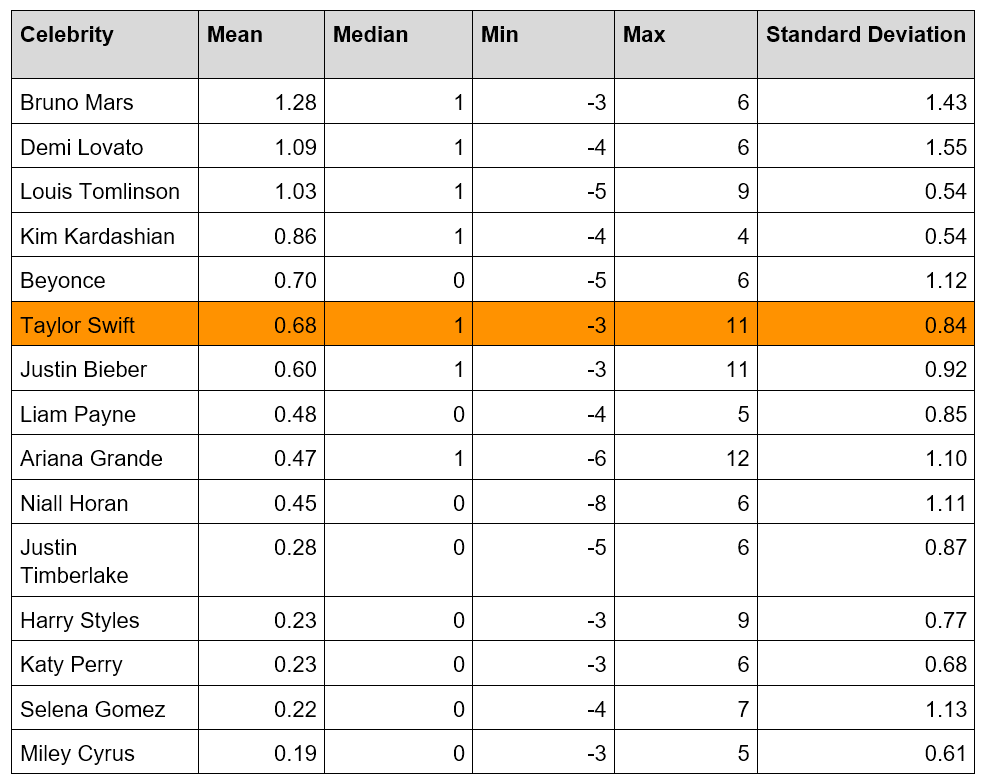
Based on mean score, Taylor sits in the top half of the table. In comparison to these other celebrities, her reputation (on Twitter at least) is above average. When looking at the standard deviation, Taylor sits somewhat near the bottom (10th highest out of 15). This represents how much variation there is between the scores of the tweets; those with a higher standard deviation are perhaps more likely to divide opinion. Taylor does not seem to be particular divisive, according to this sample of tweets.
In the following graph, we can visually inspect the summary statistics of the table, by plotting the standard deviation versus the mean.

In this plot, Taylor is close to the middle, yet her mean positivity score is higher than for most of our celebrities. There are a few exceptions. Bruno Mars and Demi Lovato’s tweets are far more positive than the rest, on average, but they also have the largest standard deviations, and thus sentiments towards them are quite wide-ranging. Meanwhile, Louis Tomlinson and Kim Kardashian’s small standard deviations would suggest more consistency in sentiment.
So, to answer my question: does Taylor Swift have a bad reputation? This limited set of data suggests not, at least not compared to those other celebrities we have looked at and not on the day these tweets were extracted. In general, sentiment towards her is positive – as measured by the mean sentiment of tweets. The claims made on her album (“This ain’t for the best, my reputation’s never been worse“) do not seem to be reflected in this research. Perhaps her reputation has recovered since the album was released or maybe it was never that bad after all.
Of course, there is plenty more I could have done with my Twitter data. My initial analysis only uses a small sample of 10,000 tweets taken one day in April 2018. It is likely that the outcome of the analysis would change depending on when I extracted the data and how many tweets I looked at. (For instance, Taylor’s recent foray into politics may have changed the situation somewhat.) An extension to this research might look at the variability of tweets about Taylor from one day to the next. Then I could carry out a longitudinal analysis of how her reputation changes over time. I could also look at more complex text analysis techniques; for example, looking for patterns in the words and forming clusters of the words that often appear together.
As for Twitter scraping, accessing tweets and running your own analysis is relatively simple and accessible to anyone with a Twitter account and R/Python. There is much that can be found out by looking at tweets, whether your interest is celebrities, politics, science or business. It is a fascinating data source and I would highly recommend investigating it for yourself.
About the author
Jennifer Snape is a statistician and data scientist with the UK Civil Service. She blogs at www.jennifersnape.com.


