![]()
To explain how this works, suppose we are building a translation application that translates from English to other languages and vice versa. Our system is to translate a sentence that contains the word 'race', which in English can be a verb but also a noun and is also true, for example, of the German equivalent word (rennen). In many languages though 'run' has a different word for the verb ('to run') and for the noun ('run'). This might sound simple, but how could a machine understand this? That is, how would we manage to tell a program that such a difference exists? One way would be to take a look at the previous or the next word, something which would probably clarify the context and decide whether 'run' is a verb or noun. The only way a machine could do this is through the assignment of a probability for a sentence in that context. This method will play an important role in the system’s performance.
The most basic machine translation works in the following way: all words and phrases in a dictionary are tagged according to their functions, for example:
|
Mike (noun N) is (verb V) a (determiner Det) student (noun N) of (preposition P) science (noun N) |
S (sentence) NP (noun phrase) VP (verb phrase) |
Tagging a body of text may require a lot of work as some of them have millions of words, but with a passage of text tagged, we can then define a grammar of the kind shown below:
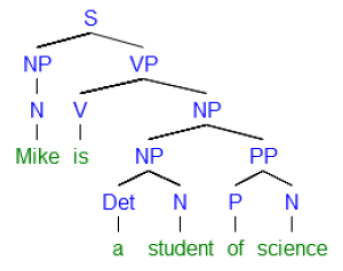
When producing an output, the tag sequence (if possible) in the language will produce a grammatical sentence and to this sequence we apply the n-gram model to determine what word is most probable to follow or precede a given word. However, we have to keep in mind that languages can be extremely different from each other. This is why we are able to translate sentences with an amount of words that varies in the input and the output. The following were translated using Google translator (December 2013):
uygarlastiramadiklarimiz → civilize the people I (…) (Turkish – English)
uygarlastiramadiklarimiz, → ones not civilized (Turkish – English)
I like bacon → rwy'n hoffi cig moch (English – Welsh)
rwy'n hoffi cig moch → maim bekana ki taraha (Welsh – Hindi)
Yo te amo → I love you (not I you love!) (Spanish – English)
Within this kind of grammar, ambiguity can be avoided. The sentence 'I saw the man with the telescope' will have one tree if the sentence denotes me as the one using the telescope, but a different one if the sentence denotes the man I see as the one with the telescope. So ideally each tree denotes one and only one reading.
In order to determine the most probable words and sequences in such a context (of selecting the adequate tree, for instance), some technique has to be used, and yes, statistics can do the job. You might think of a game like 'what is the next word', based on the Shannon’s game2 of guessing the next letter in a word. Assuming too much of the history of previous words would be counterproductive, too expensive in computational terms; so we limit ourselves to the previous one, two or three words.
Considering only the previous word, to guess which word follows is called the bigram model; considering only the two previous words, the 3gram model, and so on. (The assumption by which only some previous words are to be considered is called 'Markov assumptions', which can also be used to predict the next words.) So if the count for 'the' in the chosen corpus is 100 and the count for 'the man' is 10, we can assume that the probability of 'man' given 'the' as previous word is simply 10/100 or 1/10; that is what NLP scientists call a 'maximum likelihood estimation' for a bigram. In very simple terms, we know that if we see 'the' then we know that there is a 1/10 probability of seeing 'man' as the next word. It is a very precise mathematical formulation (here simplified) of the intuition according to when we know which word is likely to follow a number of previous words.
Using the ngram model, machine translation becomes a killer success. The algorithms are not so simple, but all of the function this way (we assume here, for simplicity sake, some general form); but its operation can be described as follows: it takes a sentence in a language as input, generates possible translations and then chooses the one with the highest probability according to the 'maximum likelihood estimation' explained above. Most human translators in the Google era do the same almost instinctively. When faced with a sentence in the input language, they first attempt a translation to see if the possible output is fluent, he or she then searches for occurrences of it. Remember that millions of sentences are being considered, if the number of occurrences is high, at least the translator may be following the right lead. If it is too low, well, better try again. It is not hard to see that in spite of some known problems with these methods, such as the assigning of zero probability to unknown sentences and words, relying on training a passage of text with considerable size, NLP tasks are able to attain outstanding levels of performance.
References
- 1. Natural Language Processing Market – Worldwide Market Forecast and Analysis (2013 – 2018)
- 2. Claude Shannon (1951), Prediction and Entropy of Printed English, in The Bell System Technical Journal 30, 5064.
- Manning, C. and Schutze, H. (1999) Foundations of Statistical Natural Language Processing. MIT Press.
- Jurafsky, D. and Martin, J. H. (2008) Speech and Language Processing. Prentice Hall. (chap46)


